

👉Part : 01
✍ Topic : Convolutional neural networks (CNNs)
Introduction
Convolutional neural networks (CNNs) emerged from the study of the brain’s visual cortex, and they have been used in image recognition since the 1980s. These studies of the visual cortex inspired the neocognitron, introduced in 1980,4 which gradually evolved into what we now call convolutional neural networks. An important milestone was a 1998 paper by Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner, which introduced the famous LeNet-5 architecture, widely used to recognize handwritten check numbers.
Artificial Intelligence has been witnessing a monumental growth in bridging the gap between the capabilities of humans and machines. Researchers and enthusiasts alike, work on numerous aspects of the field to make amazing things happen. One of many such areas is the domain of Computer Vision. The agenda for this field is to enable machines to view the world as humans do, perceive it in a similar manner and even use the knowledge for a multitude of tasks such as Image & Video recognition, Image Analysis & Classification, Media Recreation, Recommendation Systems, Natural Language Processing, etc. The advancements in Computer Vision with Deep Learning has been constructed and perfected with time, primarily over one particular algorithm — a Convolutional Neural Network.
About CNN
A convolutional neural network (CNN) is a type of artificial neural network used in image recognition and processing that is specifically designed to process pixel data.
CNNs are powerful image processing, artificial intelligence (AI) tools that use deep learning to perform both generative and descriptive tasks.They power image search services, self-driving cars, automatic video classification systems, and more. Moreover, CNNs are not restricted to visual perception: they are also successful at other tasks, such as voice recognition or natural language processing (NLP).
A simple Architecture of CNN
Nowadays, Deep Convolutional Neural Network (also called ConvNet) leverage spatial information and are therefore very well suited for image classification. A CNN mainly comprised of three layers namely convolutional layer, pooling layer and fully connected layer. These three layers can be repeatedly used to form a deep CNN architecture shown in Fig. 1. A particular organization of these layers begins with input layer and finish up with output layer. Following subsections contains description of these layers.
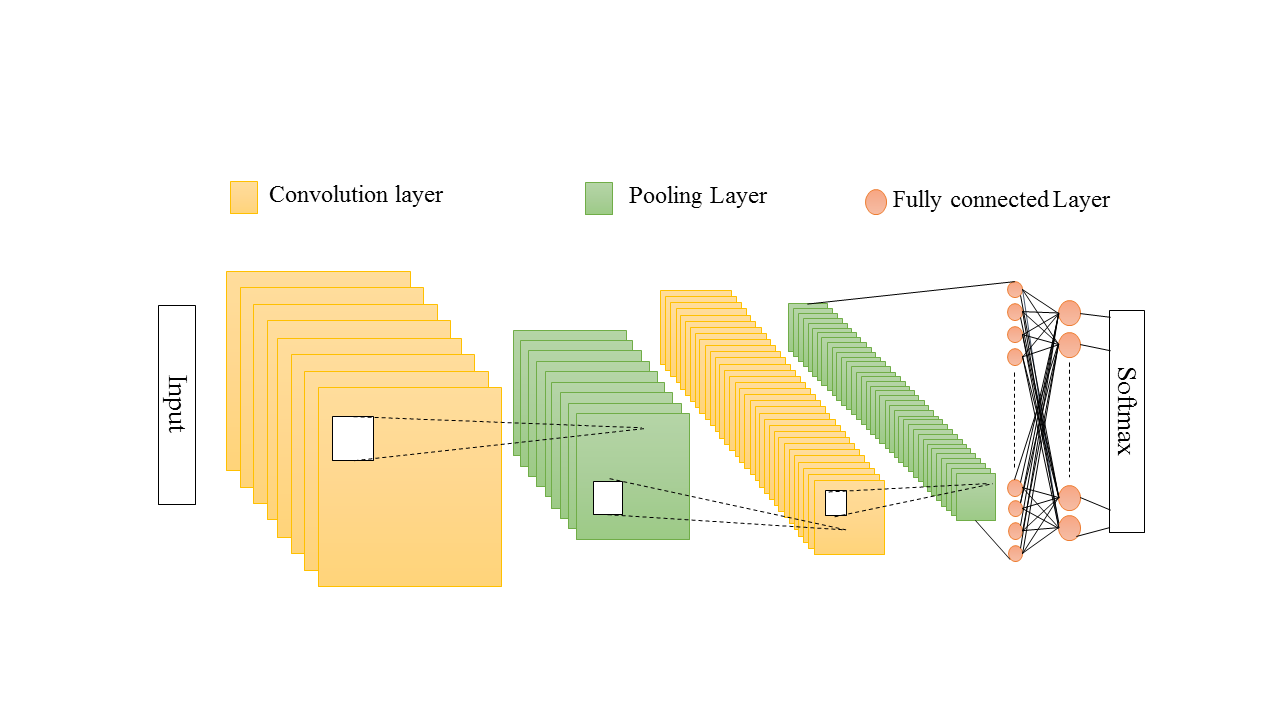
👉 Input Layer
👉 Convolution Layer
👉 Pooling Layer
👉 Fully connected Layer
👉Output Layer
CNN applications into the following areas:
- Image recognition and OCR
- Object detection for self-driving cars
- Face recognition on social media
- Image analysis in healthcare
- Face Frontal View Generation
- Generate Cartoon Characters
- Image-to-Image Translation
- Text-to-Image Translation
- Generate New Human Poses
- 3D Object Generation
- Clothing Translation
- Photograph Editing
- Video Prediction
- Photos to Emojis
- Photo Inpainting
- Super Resolution
- Photo Blending